2 前処理
2.1 データ取得元
三國志シリーズの登場人物のステータス情報は, インターネット上のいくつかの個人サイトから取得した.
- 三國志 1-713, および 12: 瀬戸大将-三國志 舞踏仙郷-
- 三國志 8: 武将リスト (web archive)
- 三國志 9: 三國志9武将一覧
- 三國志 10: 三国志10武将データ
- 三國志 11: 史実武将データ - 三國志11攻略wiki
- 三國志 13: 武将一覧 - 三國志13 攻略 WIKI
コーエーテクモ公式の資料集も存在するが, 全て紙媒体であり, 購入および転記のコスト(時間と転記時の書き間違えの可能性)を考えて利用しなかった.
rvest, SPARQLなどスクレイピングに使う各種パッケージが依存しているcurlパッケージで, これはlibcurlという外部プログラムのインターフェースにすぎない. Windowsの場合はパッケージインストール時にまとめてインストールできるが, 公式リポジトリによればLinux系は個別にインストールする必要がある. また, 今回使用するパッケージの一部はCRANに登録されていないため, remotesパッケージを予めインストールしておく必要がある.
2.2 スクレイピング
scraping.Rである.
まずは rvest パッケージで各ページを取得した. rvest はパイプ演算子でスクレイピングした html (xml) ノードデータを取得できるため, 使い勝手が良いパッケージである. 取得したページを rvest や tidyverse を使い整然データとする.
たとえば, 三国志1の武将一覧は複数ページにまたがっているが, 語尾の;p=以降のページ数を書き換えれば簡単に複数ページを取得できる.
url_1 <- "http://hima.que.ne.jp/sangokushi/sangokushi01.cgi?up1=0&keys2%2C6=&index=&IDn001=AND&sort=
up6s&print=100;p="
source1 <- list()
for (i in 1:3) {
source1[[i]] <- read_html(paste0(url_1, i - 1))
Sys.sleep(10)
}robots.txt を参照するなどして節度を守ってスクレイピングすべきであろう.
ソースファイルを取得したら一旦ローカルに保存しておくべきだろう. するとここで注意点が1つある. rvestはxml2パッケージに依存しており14, このパッケージは外部プログラムでxml(html)を制御している. このため出力されるRオブジェクトには一時的なポインタ情報しか含まれていないため, これをそのまま save()やsave.rds()で保存して再読込すると, 外部データの参照ができなくなる. よって, xmlオブジェクトは一旦文字列に変換してから保存しなければならない. 全シリーズの取得結果を保存するため, 以下のような処理を書いている15. source1から13までがそれぞれ作品ごとに取得したxml文書オブジェクトである.
sources <- map2_dfr(list(source1, source2, source3, source4, source5, source6,
source7, source8, source9, source10, source11, source12, source13),
1:13, function(x, t) tibble(x) %>% mutate(title = t, page = row_number())) %>%
mutate(html = map(x, as.character)) %>% select(-x)
write_rds(sources, here(dirname_data, "sources.rds"))2.3 データの整然化
tidying.Rである.
こうして読み込んだサイトは全て管理者が異なり, 非公式のものであるからフォーマットも違うため, それぞれ異なる処理を通して共通の構造をもつデータフレームに変換する必要がある(整然化). 多くは <table> タグを使って掲載されているため, rvest::html_table() 関数を使えば概ねうまくいく.
データの整然化(tidying)について知らない場合は, 以下のページで基本的な理念を知れる.
https://id.fnshr.info/2017/01/09/tidy-data-intro/
整然化の理念の実装は複数のパッケージで提供されるが, 現在はtidyverseというオールインワンパッケージをインストールすれば良いだろう.
関連パッケージの用途については以下で解説されている https://uribo.hatenablog.com/entry/tidy_poem2017_day4
ただし, 関数の仕様は変わることがあるので情報の鮮度に注意が必要である.読み込んだものをテーブル形式に変換する具体例として『三國志II』の場合を解説する.
# (1)
df2_header <- filter(sources, title == 2)$html[[1]] %>% read_html %>% html_node("table") %>%
html_table(header = F) %>% as.character
df2_header[1] <- "name"
df2 <- tibble()
for (i in 1:4) {
df2 <- bind_rows(df2, filter(sources, title == 2)$html[[i]] %>% read_html %>%
html_nodes("table") %>% html_table() %>% map_dfr(function(x) data.frame(matrix(as.character(x),
byrow = T, nrow = 1), stringsAsFactors = F)))
}
# (2)
df2 <- df2 %>% set_names(df2_header) %>% filter(name != "武将名") %>%
mutate_at(.vars = vars(知力, 武力, 魅力, 義理, 野望, 相性),
.funs = as.integer)
# (3)
df2 <- mutate(df2, title = "2", order = row_number()) %>% select(title,
order, name, everything())
# (4)
check_dup(df2)
df2$name[c(62, 125, 296, 24, 218, 220, 234, 279)] <- c("楽就", "辛評",
"劉曄", "賈華", "陶謙", "董衡", "馬忠 (孫呉)", "李豊 (東漢)")
check_dup(df2)この中では, (1) html内の<table>を読み込む, (2) データフレームに手動で列名を定義しなおす, (3) 各列の型を正しく認識させる, (4) 入力内容のおかしな部分がないか簡単にチェックする, という処理をおこなっている.
(4)は単純な入力ミスの修正と, 数組の同姓同名の人物を識別するための処理である. このような修正をすべきかの判断は完全に自動化することはできないため, 各シリーズごとに名前の重複がないかなどを地道に調べる必要があった. そこで処理の終盤では以下のような, データフレームを入力として名前の重複を出力する関数を使用している.
check_dup <- function(x) {
x %>% group_by(name) %>% summarise(n = n()) %>% filter(n > 1) %>% inner_join(x,
by = "name") %>% select(title, order, name, n, everything())
}おもな同姓同名の人物には以下のようなものがある.
- 張温: 東漢 (後漢) の高級官僚と, 孫呉に仕えた人物
- 張闓: 陶謙に仕えた武将と, 袁術に仕えた武将
- 張南: 袁紹に仕えたのち曹操に降伏した武将と, 蜀の武将
- 馬忠: 呉の孫権に仕えた武将と, 蜀の武将
- 李豊: 袁術に仕えた武将と, 蜀漢の武将李厳の子, そして魏の人物
これらは識別できなければならないため, 名前の末尾に「孫呉」「東漢」などと所属勢力を括弧書きで追加した. 上記の三國志IIの場合でいえば, 馬忠と李豊が当てはまる. それ以外は異なるステータスで名前の同じ項目があったため, 生没年や字の有無, ステータスの数値等から判断して修正している.
各シリーズのうち特に手間がかかったのは, 表が整然化されていない三國志9と, 表の背景色でデータを表現していた三國志12のページである. 前者は一つのセルに複数の項目が文字列として入っていた (図2.1) ため, stringr::str_split_fixed() など文字列を処理するパッケージを駆使して分解する必要があった. 後者は, 1名の人物あたり2行で掲載し, なおかつ一部の項目を文字ではなく背景色の塗りつぶしで表現していた (図2.2).
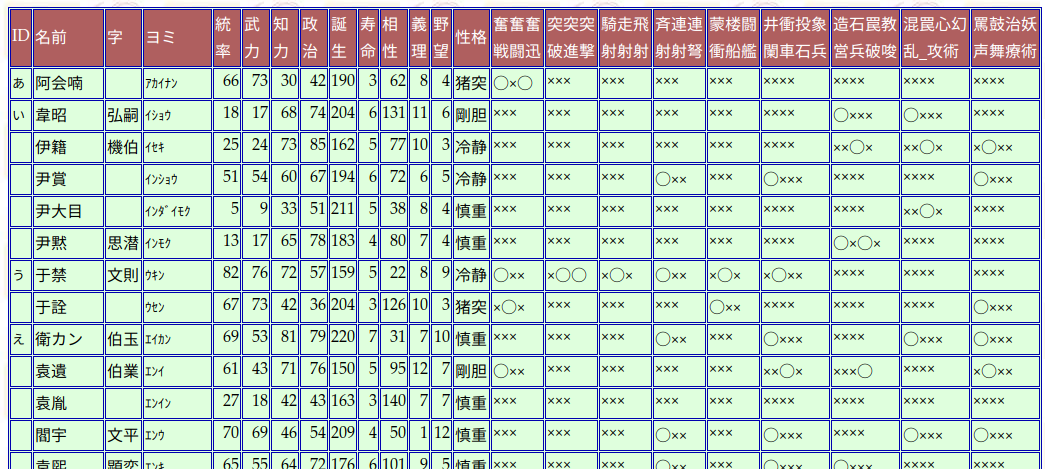
図 2.1: 三國志9 の人物一覧ページ
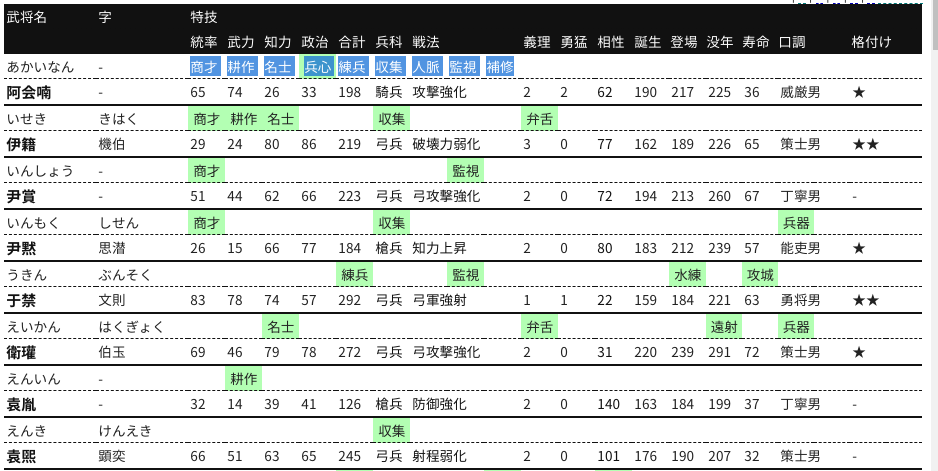
図 2.2: 三國志12 の人物一覧ページ
三國志9の場合はstringr::str_split_fixed()で文字列を1文字ごとに分解し, 個別の列に分割している.
まず, 以下はスクレイピング結果を読み込みデータフレームに変換し, 数値として扱いたい列を数値型に変換している
df9 <- filter(sources, title == 9)$html[[1]] %>% read_html %>% html_node("table") %>%
html_node("table") %>% html_table(header = T) %>% as_tibble
df9 <- filter(df9, ID != "ID") %>% mutate_all(na_if, "") %>% fill(ID) %>%
rename(name = 名前) %>% mutate_at(.vars = vars(統率, 武力, 知力,
政治, 誕生, 寿命, 相性, 義理, 野望), .funs = as.integer)次に, 問題の列を分割している. これらはある能力を持っているかどうかを表す列であり, 3, 4個の能力を1つのセルにまとめて表示していた. これをstringr::str_split_fixed()によって分解している.
df9 <- df9 %>% bind_cols(str_split_fixed(.$奮奮奮戦闘迅, pattern = "",
3) %>% data.frame %>% set_names(c("奮戦", "奮闘", "奮迅")), str_split_fixed(.$突突突破進撃,
pattern = "", 3) %>% data.frame %>% set_names(c("突破", "突進",
"突撃")), str_split_fixed(.$騎走飛射射射, pattern = "", 3) %>%
data.frame %>% set_names(c("騎射", "走射", "飛射")), str_split_fixed(.$斉連連射射弩,
pattern = "", 3) %>% data.frame %>% set_names(c("斉射", "連射",
"連弩")), str_split_fixed(.$蒙楼闘衝船艦, pattern = "", 3) %>%
data.frame %>% set_names(c("蒙衝", "楼船", "闘艦")), str_split_fixed(.$井衝投象闌車石兵,
pattern = "", 4) %>% data.frame %>% set_names(c("井闌", "衝車",
"投石", "象兵")), str_split_fixed(.$造石罠教営兵破唆, pattern = "",
4) %>% data.frame %>% set_names(c("造営", "石兵", "罠破", "教唆")),
str_split_fixed(.$`混罠心幻乱_攻術`, pattern = "", 4) %>%
data.frame %>% set_names(c("混乱", "罠", "心攻", "幻術")),
str_split_fixed(.$罵鼓治妖声舞療術, pattern = "", 4) %>% data.frame %>%
set_names(c("罵声", "鼓舞", "治療", "妖術"))) %>% select(-奮奮奮戦闘迅,
-突突突破進撃, -騎走飛射射射, -斉連連射射弩, -蒙楼闘衝船艦,
-井衝投象闌車石兵, -造石罠教営兵破唆, -`混罠心幻乱_攻術`,
-罵鼓治妖声舞療術)元の列では能力の有無を “○,” “×” という文字で表しているため, この後の処理のためにlogical型に変換する. 加えて作成者のいたずらで不要な行が含まれていたので排除している.
df9 <- mutate_at(df9, .vars = colnames(df9)[15:45], function(x) if_else(x ==
"×", F, T)) %>% rename_if(is.logical, ~paste0(.x, "lgl")) %>% mutate(性格 = factor(性格)) %>%
filter(name != "俺様") %>% mutate(title = "9", order = row_number()) %>%
select(title, order, name, everything())最後に, 三国志2と同様に人名の重複を確認して修正している.
check_dup(df9) %>% filter(!str_detect(name, "武将"))
df9$name[c(414, 501:502, 600:601)] <- c("張南 (蜀漢)", "馬忠 (孫呉)",
"馬忠 (蜀漢)", "李豊 (東漢)", "李豊 (蜀漢)")
df9$name[346] <- c("孫匡") # この後の確認で名前に字が混入していたことを発見したので修正三國志12は以下のようにテキスト情報とタグの属性をそれぞれ別に取得し結合する必要があった. マウスオーバーで表示を変えるように設定しているため, html_nodes(".on, .off")によって必要な部分を抜き出している.
最初のブロックでは後続の見通しを良くするために列名だけを取り出してdf12_headerとして整形している.
df12_header <- filter(sources, title == 12)$html[[1]] %>% read_html %>%
html_nodes("table") %>% html_table %>% .[[1]] %>% as.matrix %>% as.character
df12_header[grepl("^特技$", df12_header)] <- paste0("特技", 1:length(grep("^特技$",
df12_header)))
df12_header[1:4] <- c("名前読み", "名前", "字読み", "字")
df12_header[c(18, 20)] <- c("戦法2", "戦法3")
df12_header[38] <- "口調2"
df12_header[42] <- "格付け2"三国志12のサイトは複数ページにまたがっている. そのため, 1ページごとに処理して同じ形式のデータフレームを作成し, 最後に全て結合することにした. ここではページごとに共通する処理の関数を書いている. 特にd_flag <- ...から始まる行が, htmlタグの属性を取り出す処理である. 複雑になると思われた処理だが, rvestの力を使えば比較的シンプルに書ける.
parse_table12_by_page <- function(x, header) {
d_main <- x %>% html_nodes("table") %>% html_table %>% map(function(x) as.character(unlist(x)) %>%
matrix(nrow = 1, byrow = T) %>% as.data.frame(stringsAsFactors = F) %>%
set_names(header)) %>% bind_rows %>% filter(名前読み != "武将名")
d_flag <- x %>% html_nodes("table") %>% html_nodes(".on, .off") %>%
html_attr("class") %>% {
ifelse(. == "on", T, F)
} %>% matrix(ncol = 20, byrow = T)
d_main[sort(grep("^特技[0-9]+$", colnames(d_main)))] <- d_flag
return(as_tibble(d_main))
}各ページに並列して上記の関数を適用し, 結合する. その後列の型や名前を一括して調整した. 最後は例によって人名の調整である.
df12 <- map_dfr(map(filter(sources, title == 12)$html, read_html), function(x) parse_table12_by_page(x,
df12_header))
df12 %<>% select(-合計, -格付け, -格付け2) %>% mutate_at(.vars = vars(統率,
武力, 知力, 政治, 義理, 勇猛, 相性, 誕生, 登場, 没年,
寿命), as.integer) %>% mutate_if(is.character, function(x) na_if(x,
"-")) %>% mutate_at(.vars = vars(口調, 口調2), as.factor) %>% rename(name = 名前) %>%
mutate(title = "12", order = row_number()) %>% select(title, order,
name, everything())
check_dup(df12)
# 呉の馬忠は落選
filter(df12, str_detect(name, "馬忠|李豊|張温")) %>% select(name,
字, order, 相性, 誕生, 登場, 没年)
df12$name[c(257, 332, 403)] <- c("張温 (孫呉)", "馬忠 (蜀漢)",
"李豊 (東漢)")以上のような処理を13作品のデータに対して行い, 7,115件, 1,120名の人物データが入手できた. しかし, ここまでの例でわかるように三國志シリーズは作品ごとにステータス値の項目が異なる. この後の一括処理のため, いったん名前と登場作品以外の項目はネストしてしまう(表2.1).
list(df1, df2, df3, df4, df5, df6, df7, df8, df9, df10, df11, df12, df13) %>%
map_dfr(~group_by(.x, title, order, name) %>% nest %>% ungroup)| title | order | name | data |
|---|---|---|---|
| 1 | 1 | 伊籍 | イセキ, 74 , 86 , 18 , 28 , 75 |
| 1 | 2 | 于禁 | ウキン, 82 , 20 , 72 , 25 , 28 |
| 1 | 3 | 袁胤 | エンイン, 71 , 63 , 25 , 92 , 50 |
| 1 | 4 | 袁煕 | エンキ, 73 , 52 , 46 , 89 , 22 |
| 1 | 5 | 袁紹 | エンショウ, 35 , 54 , 82 , 98 , 86 |
| 1 | 6 | 袁尚 | エンショウ, 82 , 63 , 87 , 98 , 61 |
2.4 さらなる名寄せ処理
今回の情報源は複数の個人サイトによるもので, フォーマットも全く異なり表記にもかなりゆらぎがある. 単なる誤変換であるもの, 原典である『正史三国志』と『三国志演義』の間でもすでに食い違っているものなど, 原因は様々である. 使用するデータの品質向上のため, 当初は手動でいくつかの方法を試した.
三国志以外の登場人物を除外する
既に述べたように, 春秋戦国時代や, 魏晉時より後代の人物が隠し要素として存在する. 三国志演義が史書とは異なる創作であり, 真実がなんであるかを問題としない以上, 2世紀末の中国でチンギス=ハンが覇を唱えようが織田信長が乱入しようが, 皇帝ラインハルト率いる宇宙艦隊が遠征してこようが, 原則を言えばあらゆる創作を「三国志」として認めなければならない. しかし今回はあくまで, 三国志の人物の評価の変遷を知るのが目的である. こういった企画で採用される人物はその時代を代表する英雄であるため, しばしば非常に高いステータス値が設定されている. そういう人物が8以降の作品では数十人ほど登録されており, これを含めるかどうかで要約統計量の数値はかなり変わってくる. よって, 今回は『三国志演義』『正史三国志』『反三国志』および『花関索伝』で言及される人物16だけを対象とすることにした. この処理によって179名が除外された.
漢字が使われていない名前を検査する
まず, 正規表現で漢字以外の使われている人名を探した. 機種依存文字をカタカナ等で置き換えていたものを見つけた手動で修正した. 有名な例では, UTF-8 が普及する以前は張郃の「郃」の字に対応した文字コードがなかったため, インターネット上でしばしば「合β」と表記されていた.
そこで以下のように正規表現で漢字でない文字を含むものを取り出した上で, 既に書いたように同姓同名人物の識別のために付けた括弧付きの人名リストname_parenthesisと一致するものを排除し, 確認が必要な人名を取り出した17.
この方法では, 龐徳18, 賈詡, 郝昭, など同様の原因でカナで表記されるなど表記のゆらぎが発生している人名を122件発見した.
3字以上の名前を検査する
三国志の時代の人名は姓名それぞれ1字づつであることが多く, 3字以上の名前は珍しい. 夏侯, 諸葛, 司馬, 公孫など2字の姓は限られている. 名が2字以上になる人名も 戯 志才, 郭 攸之などかなり限られる. それ以外で3字以上の名前の多くは, 於夫羅, 卑弥呼, 都市牛利 など, 非漢民族の発音を当てたものと思われる. そこで, 名前が3字以上のものも手作業で確認してもさほど手間にならないと判断し確認した. 文字数は stringr::str_length() 関数で取得できる. その結果, 以下のような表記のゆらぎを19件見つけた. 事例の一部を抜粋する.
- 許劭/許子将. 子将は字である19.
- 金環三結/金環結: 後者は三国志3でのみ見られた. 人名に3字までの制約があったのだと思われる.
- 祝融/祝融夫人: これは誤りではないが, 同一人物の表記が異なるとその後の処理に支障を来す. 「夫人」を除外した.
- 秦宜禄/秦誼: そもそも史書で表記のゆらぎがある.
- 邢道栄/刑道栄: 「邢」をカタカナで置き換えるケースは既に見たが, 「刑」で置き換えているケースも発見.
- 劉豹/左賢王: 左賢王は南匈奴の王の称号. 作中のテキストから, 史書で左賢王の地位にあった劉豹と同定される. 劉豹は於夫羅の子.
ただし, 許劭/許子将 や, 秦宜禄/秦誼の組み合わせは, 単に3字以上の例を検索するだけでなく, 三国志の知識がなければただちには分からない. 現時点ではこのように作業する人間の予備知識なしでは名寄せ処理の品質を担保できない.
さらに, 本来の意図ではないが, 3字以上の人名に誤記を見つけた. その抜粋は以下.
- 毌丘倹/母丘倹: 子弟である秀, 甸にも同様の誤りが見られた.
- 諸葛瑾/諸葛謹: オウ偏の瑾の字があまり使われないための誤記と思われる.
- 太史亨太史享: 名の「亨」の字が微妙に違う.
出現頻度の少ない人名を検査する
字数の多い名前での表記のゆらぎはすでに確認できた. 3字以上の名前だけを見てもこれだけ表記にゆらぎがあるならば, 2字の名前でも同様にゆらぎがあると予想できる. そこで, シリーズ全作品のデータを結合した上で, 出現回数が2回以下のものを確認した. これで, 誤字をいくらか発見できると考えた. しかし, 実際には知名度の低い人物が多くピックアップされただけであり, ここから表記のゆらぎを見つけるのは難しい. 誤記・誤変換ならばソートしても対になる人名が近くにくるとも限らない.
2.5 機械学習による名寄せ処理
ここで説明する処理はimage_recognition.Rで実行している.
all.R ではこのスクリプトを読み込んでいない. 代わりにここで得られた結果をcsvにしてmerge.Rで読み込んでいる.
そこでさらなる名寄せ処理として, どうやって互いに類似する人名を取り出すか, ということを考える.
多くの自然言語処理の研究では, 文章を対象としている. しかし, すでに述べたように人名のほとんどが2字, 多くとも4字である. 形状の似ている文字を見つけるということから, 画像認識の技術を応用できないか考えてみる. 画像認識の一種としての手書き文字の認識は昔から研究されている. しかし, これは癖のある字をどう認識するかという教師あり学習の問題として扱われることが多いため, 今回の問題と合致しない.
今回の問題設定に合致するような先行研究がなかなか見つけられないため, 自分なりのアイディアとして, 人名の文字を画像データと見なし, 画像間の類似度を計算することで似たような字を見つける, と言う方法を採用した. これは表記ゆれを確実かつ漏れなく発見できるわけではないが, 総当りよりも効率よく見つけられると考えられる.
画像として表示するにはフォントが必要である. しかし入力者がどのフォントを使っていたかは特定できない. また, 一部の人名は標準的な日本語フォントに対応していないものもある. 具体的には, 呉の景帝の太子の一人である「孫𩅦」である. 「𩅦」の字は Unicode では CJK統合漢字拡張Bのカテゴリに含まれているが20, 日本語フォントで対応しているものは少ない. 中国語圏で普及しているフォントには対応しているものもあるが, 今回の目的は日本人が日本語環境で入力したデータベースの名寄せだから, できる限り日本風のフォントを使う必要がある. これに対応する日本語フォントは花園明朝Bである. よって, 文字画像にはfonts.jpで提供される花園明朝AおよびBを使うことにした.
まず人名を2つ取り出し, それぞれ文字列のビットマップ情報21に変換する.
例えば以下のような画像になる(図2.3).

図 2.3: 人名のビットマップ画像の例
それから, ビットマップ情報から特徴量を取り出す.
特徴量の取り出し方は, 今回2通りの方法を試した.
- の方法では, 特徴量は \(32\times128=4096\) 次元の数値となる22. (2) の方法は, ピクセルの並びの全ての行・列それぞれに対して, 背景色・文字色の変化の回数 (これを「微分」と呼ぶ), 文字色の割合 (これを「積分」と呼ぶ) を計算する方法である. これによって, \((32+128)\times2=320\) 次元の特徴量が得られる (実際に使用したのは\(317\)次元).
最後に, 2つの文字画像の特徴量ベクトル \(\boldsymbol{x},\boldsymbol{y}\) について, 距離 \(d(\boldsymbol{x},\boldsymbol{y})\) を計算する.
\[\begin{aligned} s(x,y):= & \frac{d(x,y)-\min d}{\max d-\min d} \end{aligned}\]
なお, このような類似度の求め方はテンプレートマッチングと呼ばれる(糟谷 and 山名 (2006)). \(d(x,y)\) の計算はユークリッド距離
\[\begin{aligned} d(\boldsymbol{x},\boldsymbol{y}):= & \left\Vert \boldsymbol{x}-\boldsymbol{y}\right\Vert=\sqrt{(\boldsymbol{x}-\boldsymbol{y})^{\top}(\boldsymbol{x}-\boldsymbol{y})}, \end{aligned}\]
とマンハッタン距離
\[\begin{aligned} d(\boldsymbol{x},\boldsymbol{y}):= & \left\Vert \boldsymbol{x}-\boldsymbol{y}\right\Vert_{1}=\sum_{k}\left|x_{k}-y_{k}\right|, \end{aligned}\]
で計算した.
これを全ての人名の組み合わせに対して実行し, min-max 正規化したものを類似度 \(s\) として, 値の大きい順にソートした.
特徴量のとり方の2通りのやり方はそれぞれ次元の大きさが全く異なるが, 提示された結果はかなり似ている. 上位30件を確認して発見した表記のゆらぎを表2.2に抜粋する.
| 名前1 | 名前2 | Manhattan | Euclid |
|---|---|---|---|
| 干糜 | 于糜 | \(4.94\) | \(4.79\) |
| 車胄 | 車冑 | \(4.87\) | \(4.93\) |
| 王凌 | 王淩 | \(4.81\) | \(5.03\) |
| 夏侯威 | 夏侯咸 | \(4.73\) | \(4.79\) |
| 呉鋼 | 呉綱 | \(4.65\) | \(4.79\) |
| 薛翊 | 薛珝 | \(4.59\) | \(4.58\) |
| 邢道栄 | 刑道栄 | \(4.58\) | \(4.00\) |
| 全禕 | 金禕 | \(4.55\) | \(4.47\) |
| 王匡 | 士匡 | \(4.52\) | \(4.45\) |
| 劉璝 | 劉潰 | \(4.46\) | \(4.47\) |
特に紛らわしいのは表2.3である. これは文字を拡大しないと気づきづらい.
| 正 | 誤 | 解説 |
|---|---|---|
| 車冑 | 車胄 | 「冑」の下 |
| 関彝 | 関彜 | 「米糸」と「米分」 |
| 鍾会 | 鐘会 | 「鐘」ではない |
新たに多くの表記ゆれを発見できたが, 一方で誤検知もある. 表2.2では, 夏侯威と夏侯咸, 全禕と金禕, 王匡と士匡との組み合わせは別人物である.
今回の2つの方法はいずれも, 1字同じだけでもかなり一致度が高くなってしまう. 結果として勘でやったほうが修正の必要な箇所を多く見つけられたので, より精度が必要である. 一方で, 鴨下 et al. (1998) はかなり古い研究で, 文字のビット数が小さく, さらに特徴量を大きく削減するなど計算量を削減しているが, 上記の結果とあまり変わらない結果が得られた. つまり, 特徴量のとり方しだいで差異をうまく表現できる余地があるのかもしれない.
そもそもなぜ表記ゆらぎが起きるかと言えば, 登録時点でのミス, 原作時点でのミスである. 前者は音や形状の似た字への誤変換, 普及している日本語フォントではカバーしていない, あるいは IME が対応していない字 (いわゆる機種依存文字) の代用, 後者は同一文献や, 創作物ごとのゆらぎがある23. 見つけ出したい表記のゆらぎの典型例を挙げてみる.
例: 原作からしてゆらぎがある24
- 李堪と李湛 (三国志演義と吉川三国志)
- 楊脩楊修
- 雷銅と雷同
- 陳羣と陳群
- 田豫と田予
例: 機種依存文字の影響で間違えやすい字: 部首が違う
- 劉璝 (正) と劉潰 (誤): 「璝」は日本語ではほぼ使われない
- 王凌 (正) と王淩 (誤): ニスイ偏が正しい.
- 鍾会 (正) と鐘会 (誤): カネではない25.
- 歩騭 (正) と歩隲 (誤): コザト偏の位置
似ているが別人の例として, 既に紹介したもの以外にも以下のようなものがある.
- 鄧艾と鄧芝
- 桓楷と桓階
以上の傾向から, 字形の平均的な一致度ではなく, 部首単位での類似を考慮して類似度を計算することができれば効率的であると予想している. また, 教師データもground-truth なモデルも用意できないため, 「なるべく少ない労力で, たまたまでもうまく表記ゆらぎを見つけられるような類似度の求め方」が得られれば良い.
2.6 [草稿] ディープラーニングでなんとかできないか?
[画像認識と言えば最近はニューラルネットワークを使った話が流行っているので, 何か応用できるものがないか探してみた. 機械学習の問題としてみれば教師なし学習で, かつ2点間の類似度を出せるものがよい. ここまで試したのは2つの文字画像のピクセル\(\boldsymbol{x},\boldsymbol{y}\) 間の距離である. 例えばユークリッド距離で,
\[\begin{aligned} d(\boldsymbol{x},\boldsymbol{y}):= & \sqrt{\left\Vert \boldsymbol{x}-\boldsymbol{y}\right\Vert}\end{aligned}\]
を2つの画像の類似度としてきた. しかしこれでは限界があることがわかったので, なんらかの適切な特徴量変換器 \(\boldsymbol{f}\) を挟んで,
\[\begin{aligned} s(\boldsymbol{x},\boldsymbol{y}):= & \sqrt{\left\Vert \boldsymbol{f}(\boldsymbol{x})-\boldsymbol{f}(\boldsymbol{y})\right\Vert_{2}} \end{aligned}\]
のような類似度計算ができるようになればいい. 機械学習の研究では, これを計量距離学習 (metric learning) という26.
ここでいくつか関連しそうな研究を紹介しておく.
Wang et al. (2014), Hoffer and Ailon (2015), Sanakoyeu, Bautista, and Ommer (2018), Turpault, Serizel, and Vincent (2019) などを参考にすると最近は計量距離学習では triplet network と呼ばれるモデルが流行しているらしい.
Zhang and Komachi (2019) では, CHASE プロジェクトのデータベースから, 文字の部首情報を取り出して教師なしニューラル機械翻訳 (UNMT) をしている27. しかしこれは画像認識ではない
Liu et al. (2017) は音素も考慮しているが, 今回は日本語での入力の問題なので少し違う. あと教師あり学習.
“In words, this encodes the pair of distances between each of x+ and x− against the reference x.”
Wang et al. (2014), Hoffer and Ailon (2015) 前者は多クラス分類だが, 後者はランキング問題
なお私は計量距離学習というトピックをこれまで全く知らなかった. 基本的な考え方を理解するために今回初めて Bellet (2013), Bellet, Habrard, and Sebban (2014) などを参照した程度である (よって見落としているだけということもありうる). このサーベイ・チュートリアル資料で紹介されているアイディアの多くは教師ありないし半教師あり学習だが, 今回は教師ラベルを作るのが面倒な場合はどうするかというのが問題である. ここでは主に Turpault, Serizel, and Vincent (2019) の提案する半教師あり学習28をもとに試してみる. まず, 従来的な2点の比較は双生児 (siamese) ネットワークと呼ばれる:
\[\begin{aligned} s_{\mathit{siamese}}(\boldsymbol{x},\boldsymbol{y}):= & \left\Vert f(\boldsymbol{x})-f(\boldsymbol{y})\right\Vert_{2}. \end{aligned}\]
一方で, 基準点 (anchor あるいは query と呼ばれる) \(\boldsymbol{x}^{a}\)に対して正例\(\boldsymbol{x}^{p}\), 負例\(\boldsymbol{x}^{n}\) の3対 (triplet) \((\boldsymbol{x}^{a},\boldsymbol{x}^{p},\boldsymbol{x}^{n})\)を考慮したのが triplet network である.
\[\begin{aligned} s_{\mathit{triplet}}(\boldsymbol{x},\boldsymbol{x}^{p},\boldsymbol{x}^{n}):= & \begin{bmatrix}\left\Vert f(\boldsymbol{x}^{a})-f(\boldsymbol{x}^{p})\right\Vert_{2}\\ \left\Vert f(\boldsymbol{x}^{a})-f(\boldsymbol{x}^{n})\right\Vert_{2} \end{bmatrix}\end{aligned}\]
これら3点の相対的な距離をもとに学習するというのが triplet network のアイディアになる. さらに, Wang et al. (2014) に従って triplet 損失を
\[\begin{aligned} L_{\mathit{triplet}}(\boldsymbol{x}^{a},\boldsymbol{x}^{p},\boldsymbol{x}^{n};\delta):= & \left\lfloor \left\Vert f(\boldsymbol{x}^{a})-f(\boldsymbol{x}^{p})\right\Vert_{2}-\left\Vert f(\boldsymbol{x}^{a})-f(\boldsymbol{x}^{n})\right\Vert_{2}+\delta\right\rfloor \end{aligned}\] で定義する.
しかし今回は教師ラベルがないため, \(\boldsymbol{x}^{p}\), \(\boldsymbol{x}^{n}\) をどう選べばいいかが分からない. そこで, Turpault, Serizel, and Vincent (2019) の提案するように, 特徴量 \(\boldsymbol{x}\) の距離で正例負例を与える.
2.7 補足: DBpedia を利用した二重チェック
fetch_dbpedia.R に書かれている.
教師なし学習による探索だけでは心もとないので, Wikipedia の記事を使った二重チェックを行った. DBpediaとは, Wikipedia を構造化したデータベースで, SPARQL によってデータを取得できる.
SPAQLの構文について手っ取り早く知りたいなら, 例えば以下のブログが簡易なチュートリアルになっており手軽に読める.
https://midoriit.com/2014/03/lod%e3%81%a8sparql%e5%85%a5%e9%96%801.html
もう少し詳しい話を知りたければ, 以下のページが参考になる.
http://www.aise.ics.saitama-u.ac.jp/~gotoh/IntroSPARQL.htmlR上でSPARQLを実行するには, 同名のSPARQLパッケージを使う. 例えば以下はウィキペディアから「三国志の登場人物」のカテゴリ登録されているページの見出しと本文を全て取得するクエリを実行している.
endpoint <- "http://ja.dbpedia.org/sparql"
query <- "
PREFIX dbpedia: <http://ja.dbpedia.org/resource/>
PREFIX dbp-owl: <http://dbpedia.org/ontology/>
PREFIX rdf: <http://www.w3.org/2000/01/rdf-schema#>
PREFIX category-ja: <http://ja.dbpedia.org/resource/Category:>
SELECT DISTINCT ?article, ?text
WHERE {
?article dbp-owl:wikiPageWikiLink category-ja:三国志の登場人物 .
?article rdf:comment ?text .
}
"
res <- SPARQL(endpoint, query)
res$results %>% filter(str_detect(o, "Category"))SRARQL()で取得した結果はリストで返され, その中のresult要素にデータフレームとして収録されている. 中身はhtmlタグなども含んでいるため, 場合によってはここでもrvestの関数を利用する必要があるかもしれない.
『三國志』シリーズの正式名称は, 10作目まではローマ数字だが, ここでは便宜上全てアラビア数字で表記する.↩︎
https://stackoverflow.com/questions/49961877/saving-xml-nodes-in-r↩︎
この問題に対して
xml2パッケージにはxml_serialize(),xml_unserialize()という関数が用意されているが, コードが長くなりむしろ不便なので私は使っていない. https://stackoverflow.com/questions/44070577/write-xml-object-to-disk↩︎実際には『反三国志』に由来する人物は馬雲騄, 花関索伝に由来する人物は鮑三娘だけであった.↩︎
全てを正規表現で表現することもできるが, 複雑すぎて可読性を損なうだろう.↩︎
龐悳という別字表記もある. また, 同時代に名前のよく似た別人として龐徳公という人物が存在するが, 今回取得した一覧には登録されていなかった.↩︎
この表記は 95年発売の『三國志V』にのみ見られ, また許劭/許子将がシリーズで初めて登場するのはこの作品である. 陳 (1974) では字で表記しているので, これの影響か.↩︎
Unicode のグリフや対応フォントの情報は, FileFormat.Info や グリフウィキ で確認できる.↩︎
今回は既に3字以上の人名の名寄せを手動で行ったが, より汎用的な性能を確認したいため, ここでは3字以上の人名も含めて実施してみる. そのため, 画像のサイズは4文字分で固定し, 字数の少ない人名は横に引き伸ばしてレンダリングしたものを使う.↩︎
どの文字画像でも変化のないピクセルは情報を持たないため除外したところ, 実際に使用できたのは4025次元だった.↩︎
まれなケースとして, 字 (あざな) が使われている場合もあるが, 当時の名の多くは1字である一方, 字の多くは2文字であり, 文字数が多いため手作業でも比較的容易に発見できた.↩︎
初期の作品はハードの制約から, より簡単な表記を選んだとも考えられる.↩︎
現代の簡体字では統一して同じ字として扱われる.↩︎
要はクラスタリングのことだと思うのだが, この単語を見かけるようになったのは最近になってからな気がする.↩︎
実装は Python の https://github.com/vincentzlt/textprep に依存している.↩︎
Turpault, Serizel, and Vincent (2019) は画像認識ではなく音声認識のテーマである↩︎